Fair Machine Learning Post Affirmative Action
By
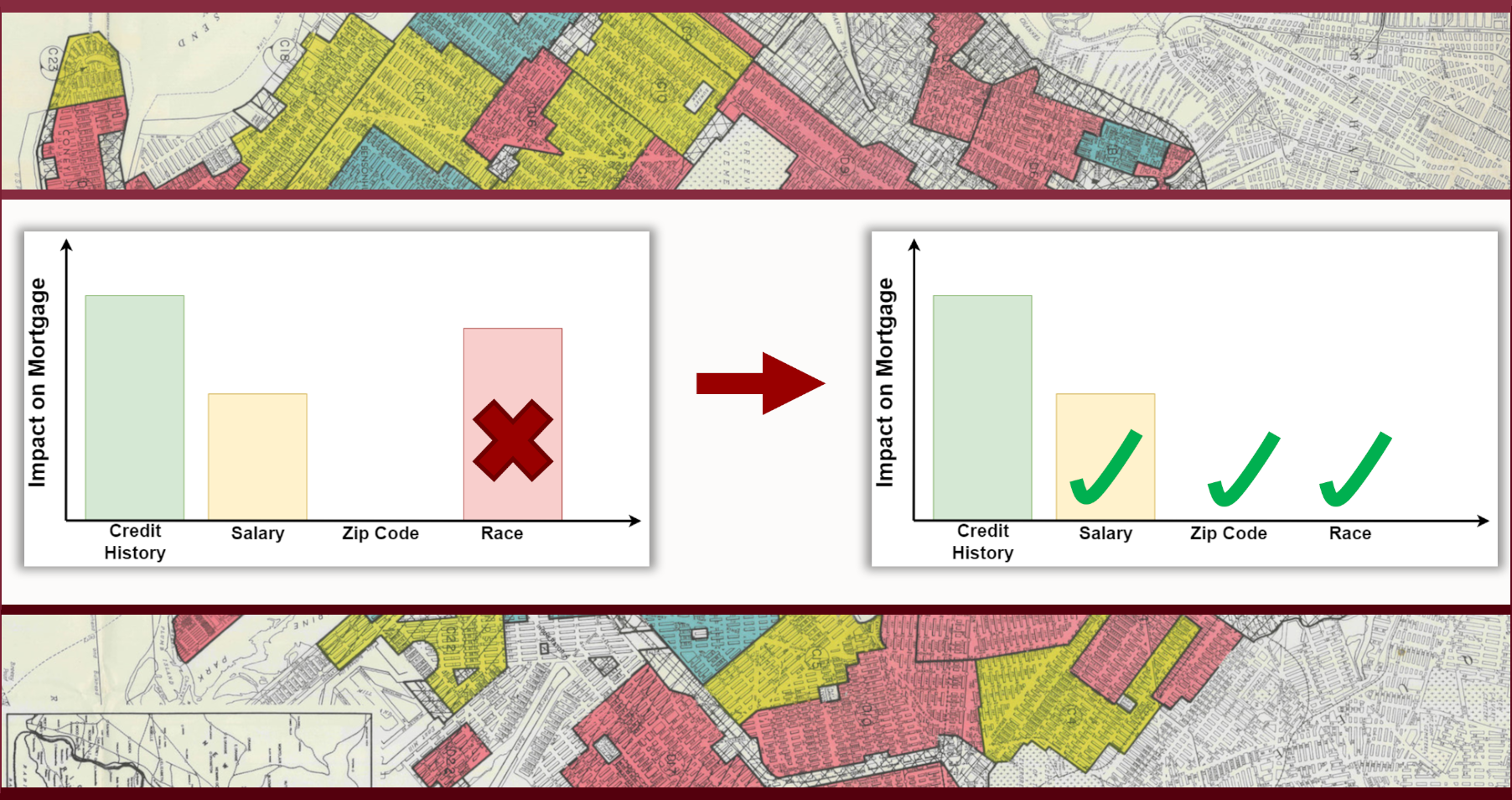
The U.S. Supreme Court, in a 6-3 decision on June 29, effectively ended the use of race in college admissions. Indeed, national polls found that a plurality of Americans – 42%, according to a poll conducted by the University of Massachusetts – agree that the policy should be discontinued, while 33% support its continued use in admissions decisions. As scholars of fair machine learning, we ponder how the Supreme Court decision shifts points of focus in the field. The most popular fair machine learning methods aim to achieve some form of “impact parity” by diminishing or removing the correlation between decisions and protected attributes, such as race or gender, similar to the 80% rule of thumb of the Equal Employment Opportunity Commission. Impact parity can be achieved by reversing historical discrimination, which corresponds to affirmative actions, or by diminishing or removing the influence of the attributes correlated with the protected attributes, which is impractical as it severely undermines model accuracy. Besides, impact disparity is not necessarily a bad thing, e.g., African-American patients suffer from a higher rate of chronic illnesses than White patients and, hence, it may be justified to admit them to care programs at a proportionally higher rate [1]. The U.S. burden-shifting framework under Title VII offers solutions alternative to impact parity. To determine employment discrimination, U.S. courts rely on the McDonnell-Douglas burden-shifting framework where the explanations, justifications, and comparisons of employment practices play a central role. Can similar methods be applied in machine learning?
In machine learning, explanations of model decisions rely on measurements of the influence that each feature has on model outcomes. Such model explanations enable meaningful comparisons between models by highlighting differences in the influence of features, including protected attributes such as race and gender, and the features correlated with them.
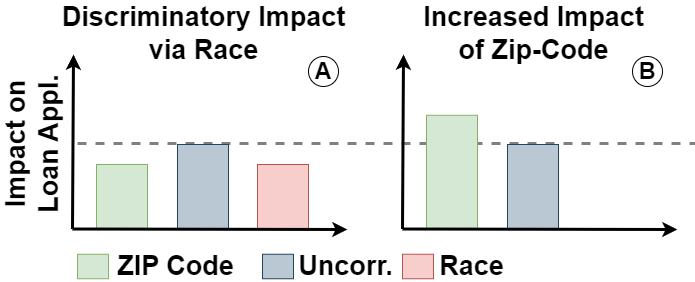
For instance, take a biased loan application system where race and zip code are available and correlated with each other as seen in the figure above. When race is used in automated decision-making, model explanations, such as measures of feature influence, will reveal that race impacts the automated decisions and, therefore, the model is discriminatory (red in Figure A). If race is removed from the training data and the model is retrained, the explanations will show that the impact of zip code increases as it is being used as a proxy for race, i.e., the model is “redlining” (green in Figure B).
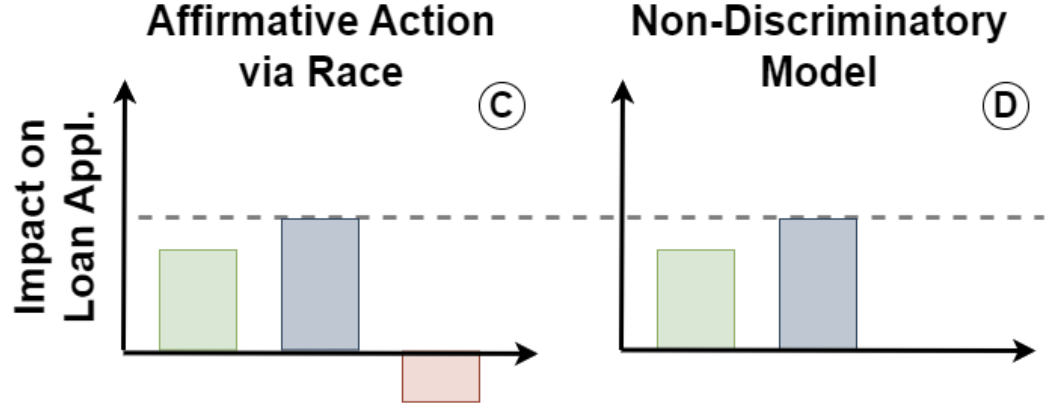
Popular fair machine learning methods that correspond to affirmative action reverse the impact of race (red in Figure C), but these methods seem less appropriate after the U.S. Supreme Court decision.
Alternatively, fair machine learning and model explanations can be combined to simultaneously drop the impact of the protected attributes, while maintaining the impact of the remaining features [2] (see our previous blog post). In our loan application example, this is equivalent to dropping the impact of race and maintaining the impact of zip code and the uncorrelated feature (Figure D). This approach does not rely on impact parity and presents a middle ground between not conducting any discrimination prevention and impact parity methods equivalent to affirmative action. Most importantly, this approach offers a middle ground between the protected, possibly intersectional [3], groups, since it does not disadvantage, nor advantage, any of the groups. Such fair learning methods seem to better align with the existing legislation, the Supreme Court decision, and democratic decision-making.
Disclaimer: A shorter version of this column will appear in an upcoming issue of Computers and Society in ACM.
References:
[1] Ziad Obermeyer, Brian Powers, Christine Vogeli, and Sendhil Mullainathan. 2019. Dissecting racial bias in an algorithm used to manage the health of populations. Science 366, 6464 (2019), 447–453.
[2] Przemyslaw A. Grabowicz, Nicholas Perello, and Aarshee Mishra. 2022. Marrying Fairness and Explainability in Supervised Learning. ACM Conference on Fairness, Accountability, and Transparency (FAccT) (2022).
[3] Przemyslaw A. Grabowicz, Nicholas Perello, and Kenta Takatsu. 2023. Learning from Discriminatory Training Data. AAAI/ACM Conference on Artificial Intelligence, Ethics, and Society (AIES) (2023).