Consider an n x n Gaussian kernel matrix corresponding to n input points in d dimensions. We show that one can compute a relative error approximation to the sum of entries in this matrix in just O(dn^{2/3}) time. This is significantly sublinear in the number of entries in the matrix – which is n^2. Our … Continue reading "Paper: Faster Kernel Matrix Algebra via Density Estimation"
Read MoreTag: icml
Paper: DeepWalking Backwards: From Node Embeddings Back to Graphs
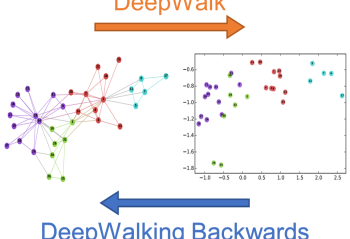
We investigate whether node embeddings, which are vector representations of graph nodes, can be inverted to approximately recover the graph used to generate them. We present algorithms that invert embeddings from the popular DeepWalk method. In experiments on real-world networks, we find that significant information about the original graph, such as specific edges, is often … Continue reading "Paper: DeepWalking Backwards: From Node Embeddings Back to Graphs"
Read MorePaper: How and Why to Use Experimental Data to Evaluate Methods for Observational Causal Inference
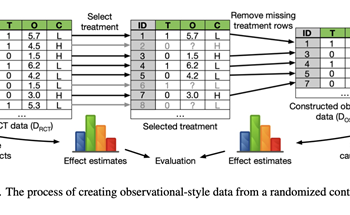
Rectangular matrix-vector products are used extensively throughout machine learning and are fundamental to neural networks such as multi-layer perceptrons, but are notably absent as normalizing flow layers. This Methods that infer causal dependence from observational data are central to many areas of science, including medicine, economics, and the social sciences. We describe and analyze observational … Continue reading "Paper: How and Why to Use Experimental Data to Evaluate Methods for Observational Causal Inference"
Read MorePaper: Posterior Value Functions: Hindsight Baselines for Policy Gradient Methods
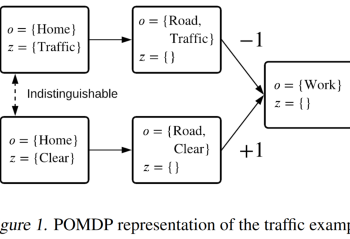
Hindsight allows reinforcement learning agents to leverage new observations to make inferences about earlier states and transitions. In this paper, we exploit the idea of hindsight and introduce posterior value functions. Posterior value functions are computed by inferring the posterior distribution over hidden components of the state in previous timesteps and can be used to … Continue reading "Paper: Posterior Value Functions: Hindsight Baselines for Policy Gradient Methods"
Read MorePaper: Towards Practical Mean Bounds for Small Samples
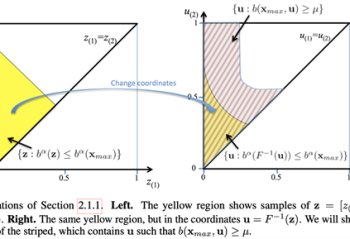
Historically, to bound the mean for small sample sizes, practitioners have had to choose between using methods with unrealistic assumptions about the unknown distribution (e.g., Gaussianity) and methods like Hoeffding’s inequality that use weaker assumptions but produce much looser (wider) intervals. In 1969, Anderson proposed a mean confidence interval strictly better than or equal to … Continue reading "Paper: Towards Practical Mean Bounds for Small Samples"
Read MorePaper: On the Difficulty of Unbiased Alpha Divergence Minimization
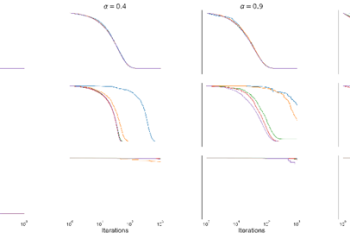
Short description: Variational inference approximates a target distribution with a simpler one. While traditional inference minimizes the “inclusive” KL-divergence, several algorithms have recently been proposed to minimize other divergences. Experimentally, however, these algorithms often seem to fail to converge. In this paper we analyze the variance of the underlying estimators for these papers. Our results … Continue reading "Paper: On the Difficulty of Unbiased Alpha Divergence Minimization"
Read MorePaper: High Confidence Generalization for Reinforcement Learning
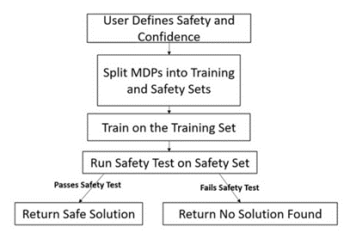
We present several classes of reinforcement learning algorithms that safely generalize to Markov decision processes (MDPs) not seen during training. Specifically, we study the setting in which some set of MDPs is accessible for training. For various definitions of safety, our algorithms give probabilistic guarantees that agents can safely generalize to MDPs that are sampled … Continue reading "Paper: High Confidence Generalization for Reinforcement Learning"
Read More