How to train models that do not propagate discrimination?
By
Powerful machine learning models can automatize decisions in critical areas of human lives, such as criminal pre-trial detention and hiring. These models are often trained on large datasets of historical decisions. However, past discriminatory human behavior may have tainted these decisions and datasets with discimination. Therefore, it is imperative to ask how can we ensure that models trained on such datasets do not discriminate against a certain race, gender, or protected group? We provide an answer based on our research publication, which was recently accepted to a premier conference on fairness, accountability, and transparency, ACM FAccT.
Disparate Impact v. Business Necessity Showdown
Legal systems prohibit discrimination in a number of contexts. For example, the U.S. Civil Rights Acts outlaw discrimination in employment and housing. The doctrine of disparate impact typically is operationalized via the well-known 80% rule of thumb, which says that the fraction of hired candidates representing a certain protected group, e.g., females, should be at least 80% of the fraction of hired candidates representing other protected groups, e.g., males.
If a particular employment practice has a disparate impact based on race, color, religion, sex, or national origin, then the employer must “demonstrate that the challenged practice is job related for the position in question and consistent with business necessity”1. For instance, the prerequisite for sufficient upper-body strength among firefighters may lead to the violation of the 80% rule w.r.t. gender groups, but this requirement could be justified by business necessity. This reasoning was applied in the Supreme Court case Ricci v. DeStefano, which justified the usage of a test for promotion to a management position of firefighters, despite its disparate impact.
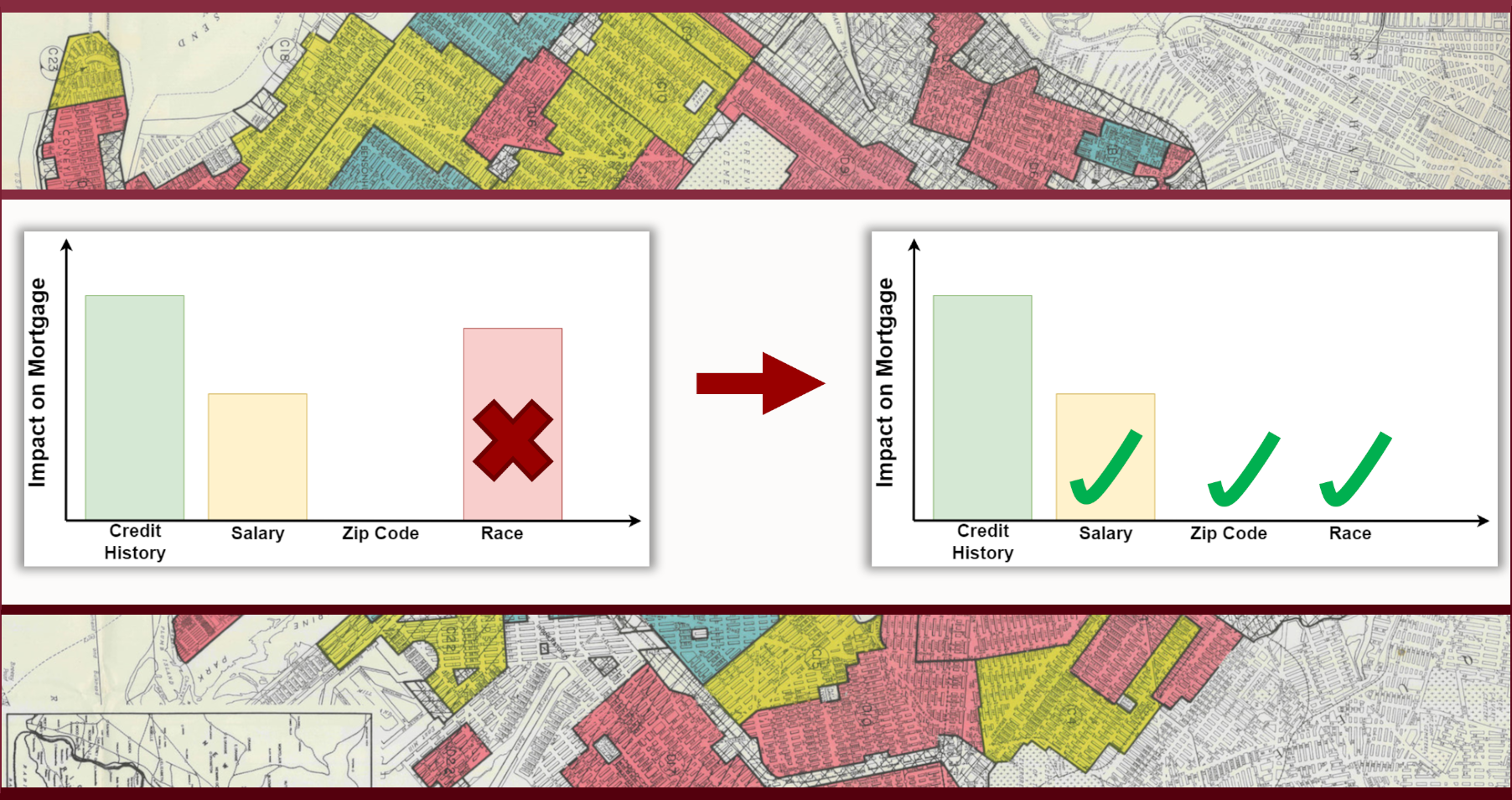
Unfortunately, the business necessity clause leaves space for a loophole. Redundant or irrelevant prerequisites could be introduced in decision-making to discriminate under a pretext of business necessity, as in the historical events known as redlining where banks denied services to zip codes inhabited predominantly by people of color. This loophole is particularly easy to exploit for machine learning algorithms. In a blind pursuit for model accuracy, learning algorithms can automatically find surprisingly accurate proxies of protected groups in training datasets and propagate discrimination by skyrocketing the impact of respective proxy features on model outcomes, unless we explicitly prevent them from doing that…
Next, using the following hypothetical example of hiring automation, we will illustrate and compare three different learning methods that aim to prevent discrimination, including our new method (FaX AI) that prevents the aforementioned loophole.
Hypothetical Case of Hiring Automation
Say we want to create a machine learning system to decide who our company should hire from a pool of applicants with college degrees. Using our company’s past and, possibly, biased hiring history we put together training data with the following information from applicants:
- The legibility of their resume (assuming we can objectively score this) ?
- Whether they have a 2 year or a 4 year degree ?
- Whether they went to a public or a private college/university ?
- Their race ?
- The hiring outcome (Yes/No) ?
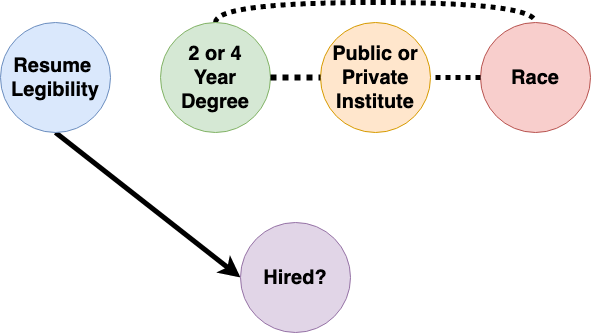
Let’s say that the following graphical model represents the biased decision-making process. The directed edges correspond to causal relations, while the dashed edges correspond to non-causal associations, e.g., correlations between the respective attributes.
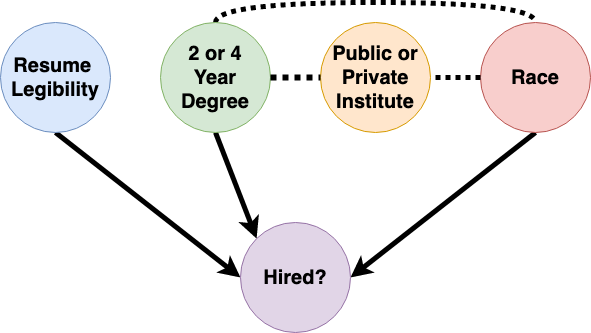
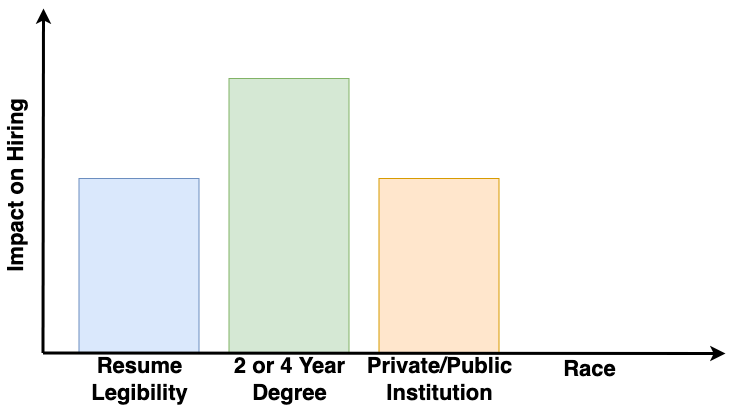
Since there was a casual relation between race and our hiring outcomes in the above process, we say that our historical hiring model was directly discriminatory. The goal of standard learning models is to obtain a model trained on a dataset that best predicts the target decisions. If the dataset is tainted by discrimination, like in our example, then models trained using it can perpetuate this discimination. Say that we trained a standard supervised learning model on our hiring dataset and it produces the following measures of impact (various feature influence measures from explainability literature could be used here, e.g., SHAP):
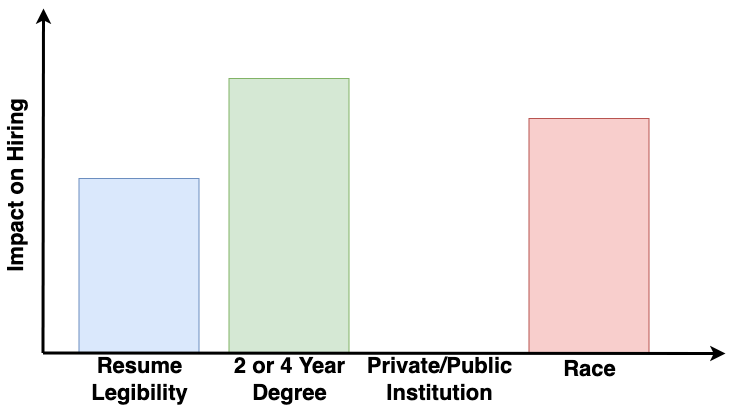
As we can see above, race has an impact on our trained model’s output for hiring decisions. Therefore, we can say that it discriminates directly. Our company definitely wants to make sure that we do not perpetuate this discrimination by race. How can we accomplish this goal?
Standard Learning Without Race
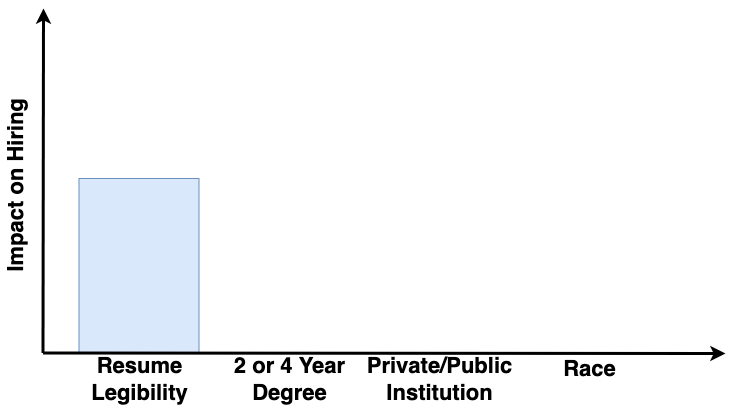
To avoid direct discrimination, we can drop the protected feature, race, when training a model using standard machine learning. This, however, is too naive and results in the following graphic model and feature impact measures.
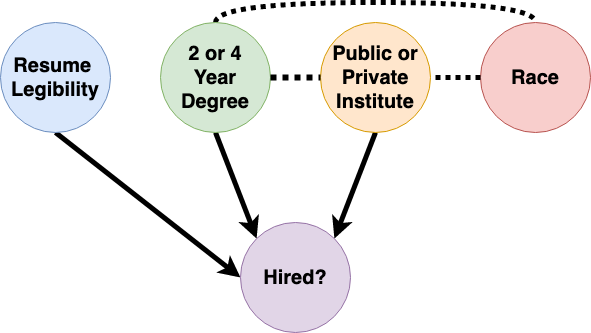
This approach removes the impact of race from the model, however, it introduces the impact of “public or private institution”, a proxy feature associated with race. We refer to this as the inducement of indirect discrimination. With the absence of protected feature, this approach uses related feature(s) as a proxy, thus inducing indirect discrimination, which is as illegal as redlining.
Learning Methods Preventing Disparate Impact
Alternatively, we can try to use methods based on well-known fairness objectives, such as the ones preventing disparate impact and treatment2 that lead to the following graphic model and feature impact:
While this method removes the impact of all features related to race, including the information about an applicant’s degree, it would significantly reduce model accuracy. However, if the information about an applicant’s degree is relevant to the job, then its usage may be legally permitted for determining hiring outcomes, which would prevent the accuracy loss.
Fair and eXplainable Artificial Intelligence (FaX AI)
In our publication, we introduced a new learning method that permits the usage of features associated with the protected groups for business necessity reasons and drops the protected attribute from the model without inducing indirect discrimination through proxy features. This results in the following graphic model and feature impact measures in our hiring example:
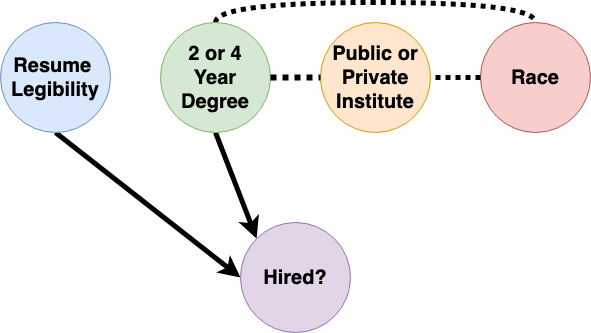
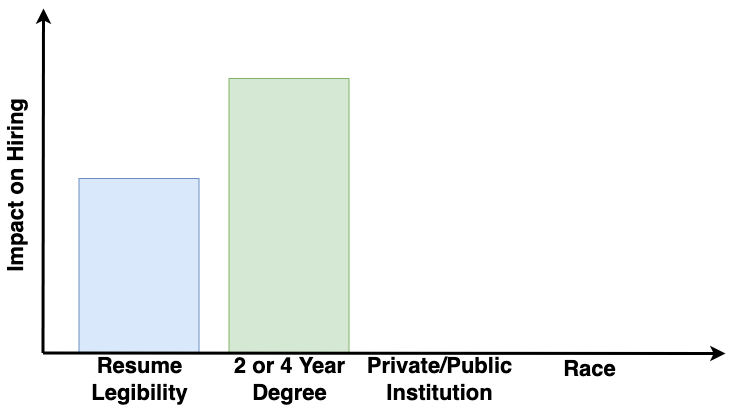
This method permits the usage of applicants’ undergraduate degree type and removes the impact of the protected feature, race, without introducing an impact from “public or private institution” on the model’s output. The method prevents discrimination propagation and preserves model accuracy. From a technical perspective, the method is a simple and computationally efficient post-processing technique of a model of your choice, e.g., an expectation over a marginal distribution of the protected attribute (see details in our publication).
Summary
The learning methods described above can be ordered in terms of the strength of discrimination prevention, from the methods that do not have any discrimination prevention to the ones that aim to remove any association between outcomes and protected groups:
| Learning method | Discrimination prevention strength | Legal?3 |
|---|---|---|
| Standard learning | 0. No prevention | No |
| Standard learning dropping the protected feature | 1. Direct discrimination prevented, but inducement of indirect discrimination allowed | Arguably no |
| Fair and eXplainable artificial intelligence | 2. Direct discrimination and inducement of indirect discrimination prevented | Arguably yes |
| Learning methods based on impact parity | 3. Affirmative action | Yes |
Businesses that are interested in using machine learning models for high-stake decision-making have a couple of legally defensible choices. First, they may embrace voluntary affirmative action and choose to use learning methods that combat disparate impact. These models, however, may be less accurate than models trained using other learning methods. Second option is to use the FaX AI method, since it permits the usage of attributes associated with the protected groups to a limited extent, which helps to develop more accurate models. We would argue that the method offers a minimal viable solution complying with legal requirements.To use FaX AI with your favorite models check out the FaX AI code library. If you are interested in learning the details of the FaX AI methods, please see our research paper.
1 https://www.law.cornell.edu/uscode/text/42/2000e-2
2 Various algorithms have been proposed to this end, e.g., the approach by Zafar et al. and the Exponentiated Gradient Reduction available in the AI360 library.
3 The information in this column is only for illustrative purposes. It assumes that the training data was tainted by discrimination and that all information necessary to accurately model decisions is available and correctly used for model development.