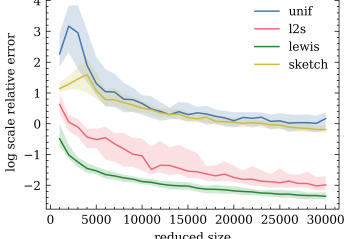
We show how to sample a small subset of points from a larger dataset, such that if we solve logistic regression, hinge loss regression (i.e., soft margin SVM), or a number of other problems used to train linear classifiers on the sampled dataset, then we obtain a near optimal solution for the full dataset. This … Continue reading "Paper: Coresets for Classification – Simplified and Strengthened"
Read More