Paper: Cooperative Stochastic Bandits with Asynchronous Agents and Constrained Feedback
By
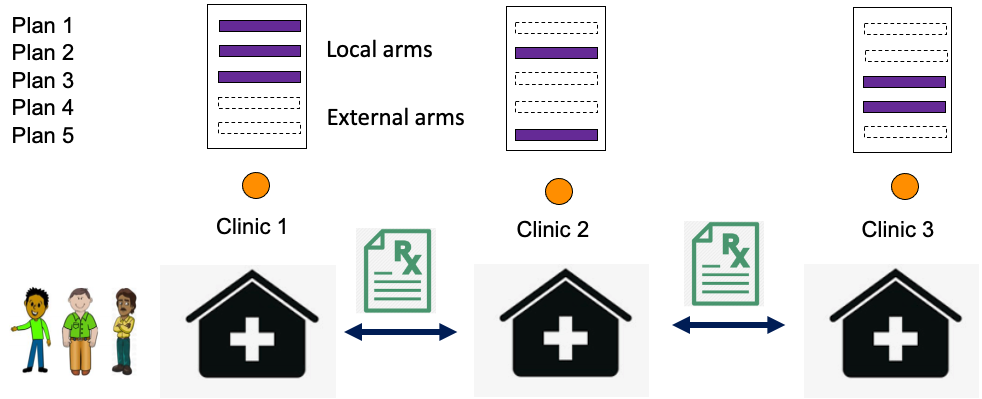
This paper studies a cooperative multi-armed bandit problem with M agents cooperating together to solve the same instance of a K-armed stochastic bandit problem. The agents are heterogeneous in their limited access to a local subset of arms; and their decision-making rounds. The goal is to find the global optimal arm and agents are able to pull any arm, however, they observe the reward only when the selected arm is local. The challenge is a tradeoff for agents between pulling a local arm with the possibility of observing the feedback, or relying on the observations of other agents that might occur at different rates. We propose a two-stage learning algorithm, whose regret matches the regret lower bound up to a K factor.