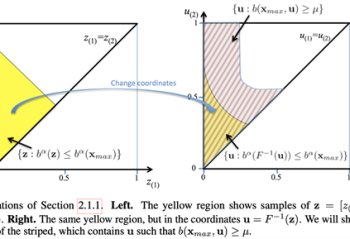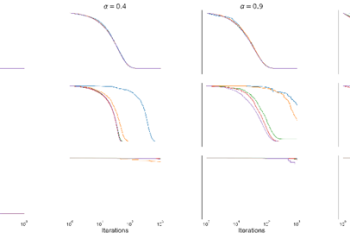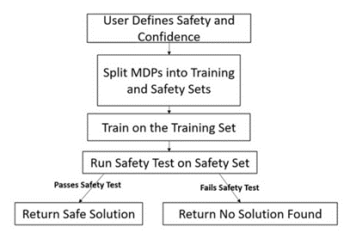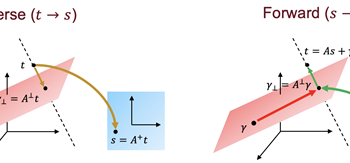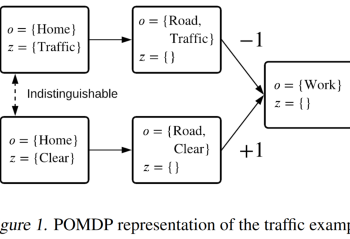
Hindsight allows reinforcement learning agents to leverage new observations to make inferences about earlier states and transitions. In this paper, we exploit the idea of hindsight and introduce posterior value functions. Posterior value functions are computed by inferring the posterior distribution over hidden components of the state in previous timesteps and can be used to … Continue reading "Paper: Posterior Value Functions: Hindsight Baselines for Policy Gradient Methods"
Read More