Paper: Pareto-Optimal Learning-Augmented Algorithms for Online Conversion Problems
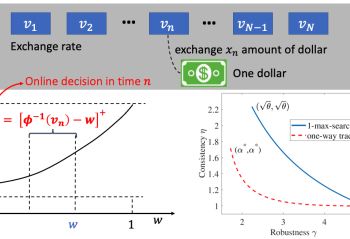
In this work, we leverage machine-learned predictions to design competitive algorithms for online conversion problems with the goal of improving the competitive ratio when predictions are accurate (i.e., consistency), while also guaranteeing a worst-case competitive ratio regardless of the prediction quality (i.e., robustness). We unify the algorithmic design of both integral and fractional conversion problems, … Continue reading "Paper: Pareto-Optimal Learning-Augmented Algorithms for Online Conversion Problems"
Read MorePaper: Relaxed Marginal Consistency for Differentially Private Query Answering
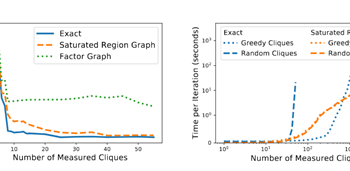
Differentially private algorithms for answering database queries often involve reconstruction of a discrete distribution from noisy measurements. PRIVATE-PGM is a recent exact inference based technique that scales well for sparse measurements and provides consistent and accurate answers. However it fails to run in high dimensions with dense measurements. This work overcomes the scalability limitation of … Continue reading "Paper: Relaxed Marginal Consistency for Differentially Private Query Answering"
Read MorePaper: Amortized Variational Inference for Simple Hierarchical Models
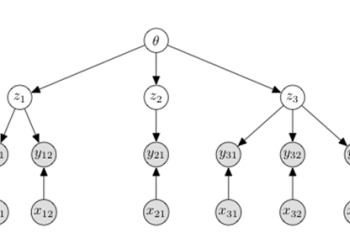
It is difficult to use subsampling with variational inference in hierarchical models since the number of local latent variables scales with the dataset. Thus, inference in hierarchical models remains a challenge at large scale. It is helpful to use a variational family with structure matching the posterior, but optimization is still slow due to the … Continue reading "Paper: Amortized Variational Inference for Simple Hierarchical Models"
Read MorePaper: MCMC Variational Inference via Uncorrected Hamiltonian Annealing
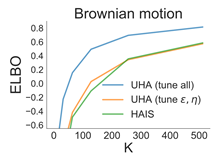
When faced with sequential decision-making problems, it is often useful to be able to predict what would Annealed Importance Sampling (AIS) with Hamiltonian MCMC can be used to get tight lower bounds on a distribution’s (log) normalization constant. Its main drawback is that it uses non-differentiable transition kernels, which makes tuning its many parameters hard. … Continue reading "Paper: MCMC Variational Inference via Uncorrected Hamiltonian Annealing"
Read MorePaper: Universal Off-Policy Evaluation

When faced with sequential decision-making problems, it is often useful to be able to predict what would happen if decisions were made using a new policy. Those predictions must often be based on data collected under some previously used decision-making rule. Many previous methods enable such off-policy (or counterfactual) estimation of the expected value of … Continue reading "Paper: Universal Off-Policy Evaluation"
Read MorePaper: Structural Credit Assignment in Neural Networks using Reinforcement Learning
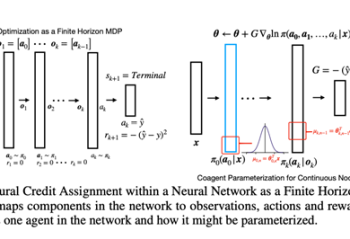
Consider an n x n Gaussian kernel matrix corresponding to n input points in d dimensions. We show that one In this work, we revisit REINFORCE and investigate if we can leverage other reinforcement learning approaches to improve learning. We formalize training a neural network as a finite-horizon reinforcement learning problem and discuss how this … Continue reading "Paper: Structural Credit Assignment in Neural Networks using Reinforcement Learning"
Read MorePaper: Faster Kernel Matrix Algebra via Density Estimation
Consider an n x n Gaussian kernel matrix corresponding to n input points in d dimensions. We show that one can compute a relative error approximation to the sum of entries in this matrix in just O(dn^{2/3}) time. This is significantly sublinear in the number of entries in the matrix – which is n^2. Our … Continue reading "Paper: Faster Kernel Matrix Algebra via Density Estimation"
Read MorePaper: DeepWalking Backwards: From Node Embeddings Back to Graphs
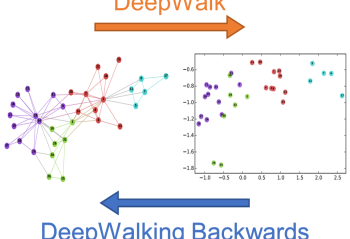
We investigate whether node embeddings, which are vector representations of graph nodes, can be inverted to approximately recover the graph used to generate them. We present algorithms that invert embeddings from the popular DeepWalk method. In experiments on real-world networks, we find that significant information about the original graph, such as specific edges, is often … Continue reading "Paper: DeepWalking Backwards: From Node Embeddings Back to Graphs"
Read MorePaper: How and Why to Use Experimental Data to Evaluate Methods for Observational Causal Inference
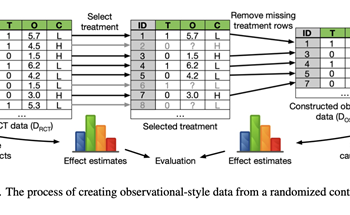
Rectangular matrix-vector products are used extensively throughout machine learning and are fundamental to neural networks such as multi-layer perceptrons, but are notably absent as normalizing flow layers. This Methods that infer causal dependence from observational data are central to many areas of science, including medicine, economics, and the social sciences. We describe and analyze observational … Continue reading "Paper: How and Why to Use Experimental Data to Evaluate Methods for Observational Causal Inference"
Read MorePaper: Towards Practical Mean Bounds for Small Samples
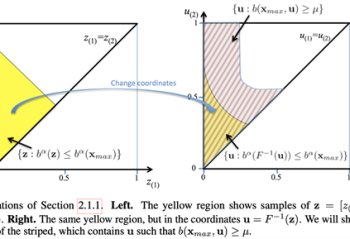
Historically, to bound the mean for small sample sizes, practitioners have had to choose between using methods with unrealistic assumptions about the unknown distribution (e.g., Gaussianity) and methods like Hoeffding’s inequality that use weaker assumptions but produce much looser (wider) intervals. In 1969, Anderson proposed a mean confidence interval strictly better than or equal to … Continue reading "Paper: Towards Practical Mean Bounds for Small Samples"
Read More