Model Explanations with Differential Privacy
By
Full Abstract:
Black-box machine learning models are used in critical decision-making domains, giving rise to several calls for more algorithmic transparency. The drawback is that model explanations can leak information about the data used to generate them, thus undermining data privacy. To address this issue, we propose differentially private algorithms to construct feature-based model explanations. We design an adaptive differentially private gradient descent algorithm, that finds the minimal privacy budget required to produce accurate explanations. It reduces the overall privacy loss on explanation data, by adaptively reusing past differentially private explanations. It also amplifies the privacy guarantees with respect to the training data. Finally, we evaluate the implications of differentially private models and our privacy mechanisms on the quality of model explanations.
General Summary:
Can we explain the decisions of automated decision makers while maintaining user privacy? In this paper, we explore this question. Our aim was to identify a method for explaining models that preserves user privacy on the one hand, but ensures explanation quality on the other.
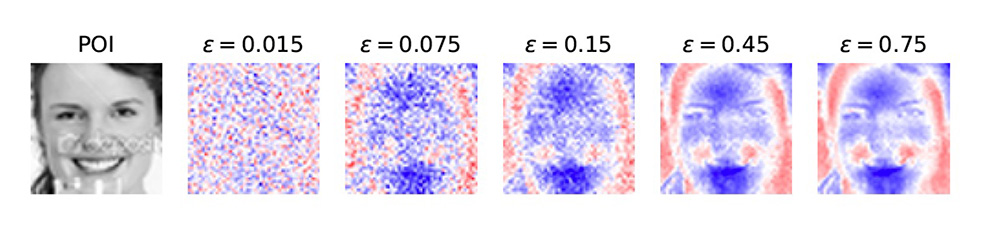
The idea is simple: introduce a small amount of noise into the process of computing the model explanation, so as to “mask” potential avenues for information leakage. This is also known in the literature as differential privacy: it is difficult to tell whether a given data point was used to compute our explanation just by looking at it.
The amount of random noise we introduce cannot be too large: if it is then our explanations wouldn’t be any good – they’ll just be overwhelmed by the noise we inject. So the challenge is to compute exactly how much randomness is enough to protect user data, while maintaining good quality guarantees.
It is convenient to think about the privacy protection as a “budget” – whenever we release information, we pay a small amount of privacy budget to protect it. This budget is finite, so we can’t keep releasing explanations without spending it all! To maximize the number of explanations we can safely release, we explore a “reduce, reuse, recycle” paradigm.
First, we try to reduce the number of computation steps we take to compute explanations, by looking at the explanations we have already released. If they offer useful information, we can use it to reduce the privacy spending for the current explanation.
Second, we try to reuse explanations if possible: if a previously released explanation is close to the one we might compute, we may as well release it instead of spending our privacy budget on computing a new one.
Finally, once we have exhausted our privacy budget, we recycle the set of previously computed explanations, and use it to compute new ones. Since the explanations we have already released are protected, we don’t have to worry about them leaking any private information.
We test our framework on a number of different datasets: facial recognition (trying to predict whether a person is happy or sad), movie reviews (trying to predict whether a review is positive or negative), and financial data (trying to predict whether someone is eligible for a loan). In all cases, our method is able to provide several thousand explanations on a modest privacy budget. In addition, our reduce/reuse/recycle approach yields significant savings in the privacy budget.