
Projects
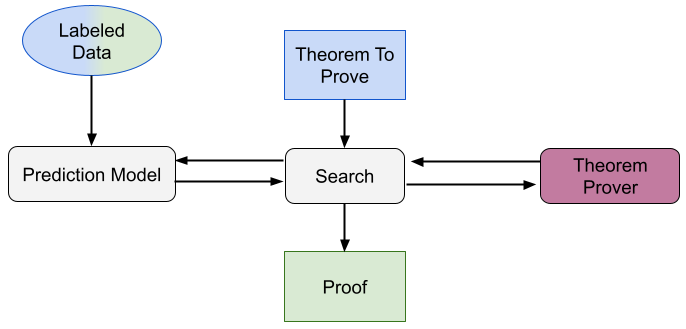
Automated formal verification
Formal verification—proving the correctness of software—is one of the most effective ways of improving software quality. But, despite significant help from interactive theorem provers and automation tools such as hammers, writing the required proofs is an incredibly difficult, time consuming, and error prone manual process. My work has pioneered ways to use natural language processing to synthesize formal verification proofs. Automating proof synthesis can drastically reduce costs of formal verification and improve software quality. The unique nature of formal verification allows us to combine multiple models to fully automatically prove 33.8% of formal verification theorems in Coq (ICSE’22 Distinguished Paper Award), and use large language models to synthesize guaranteed-correct proofs for 65.7% of mathematical theorems in Isabelle (ESEC/FSE’23 Distinguished Paper Award). Combining proof state with partially-written proofs and incorporating identifiers can both help improve proof synthesis. Watch a video of Proofster, our web-based proof-synthesis interface.

Provably fair and safe software
Today, increasingly more software uses artificial intelligence. Unfortunately, recent investigations have shown that such systems can discriminate and be unsafe for humans. My work identified that numerous challenges in this space are fundamentally software engineering challenges, founded the field of software fairness (ESEC/FSE’17 Distinguished Paper Award), established a roadmap for this field, and developed the first machine learning algorithms that provide provable guarantees that learned models adhere to safety and fairness requirements. Next, we showed that such guarantees can hold for contextual bandits and when the training data comes from a different distribution than the data the system is applied to at runtime. Importantly, recent work has shown that, sometimes, optimizing short-term fairness constraints can lead to adverse outcomes in the long term. Our most recent work showed that machine learning can guarantee constraints on both, short term and long-term, delayed impact by formulating the learning goal as simultaneously a fairness-constrained classification problem and a reinforcement learning problem for optimizing the long-term impact. The central goal of our work is to make safe and fair machine learning accessible to software engineers, who have neither extensive machine learning expertise nor are themselves experts in the application domains that require fairness and safety, such as healthcare or law (video).
Trust in machine learning
Increasingly, software systems use machine learning. Whether users understand how this technology functions can fundamentally affect their trust in these systems. We study how aspects of machine learning, such as precision and bias, affect people’s perception and trust, and how explainability techniques can better educate users, engineers, and policymakers into making better, evidence-based decisions about machine learning. Our findings include that bias affects men and women differently when making trust-based decisions, and that visualization design choices have a significant impact on bias perception, and on the resulting trust.
High-quality automated program repair
Software bugs are incredibly costly, but so is software debugging, as more new bugs are reported every day than developers can handle. Automatic program repair has the potential to significantly reduce time and cost of debugging. But our work has shown that such techniques can often break as much functionality as they repair. Our work has focused on improving the quality of automated program repair. We developed an objective methodology for measuring overfitting that leads to low-quality repairs, which has become ubiquitous in the field and has led to significant improvements in repair quality. Our controlled user study found that automated repair positively impacts the human-driven debugging process, which is how it is used in industry today.
Past Projects
Proactive detection of collaboration conflicts
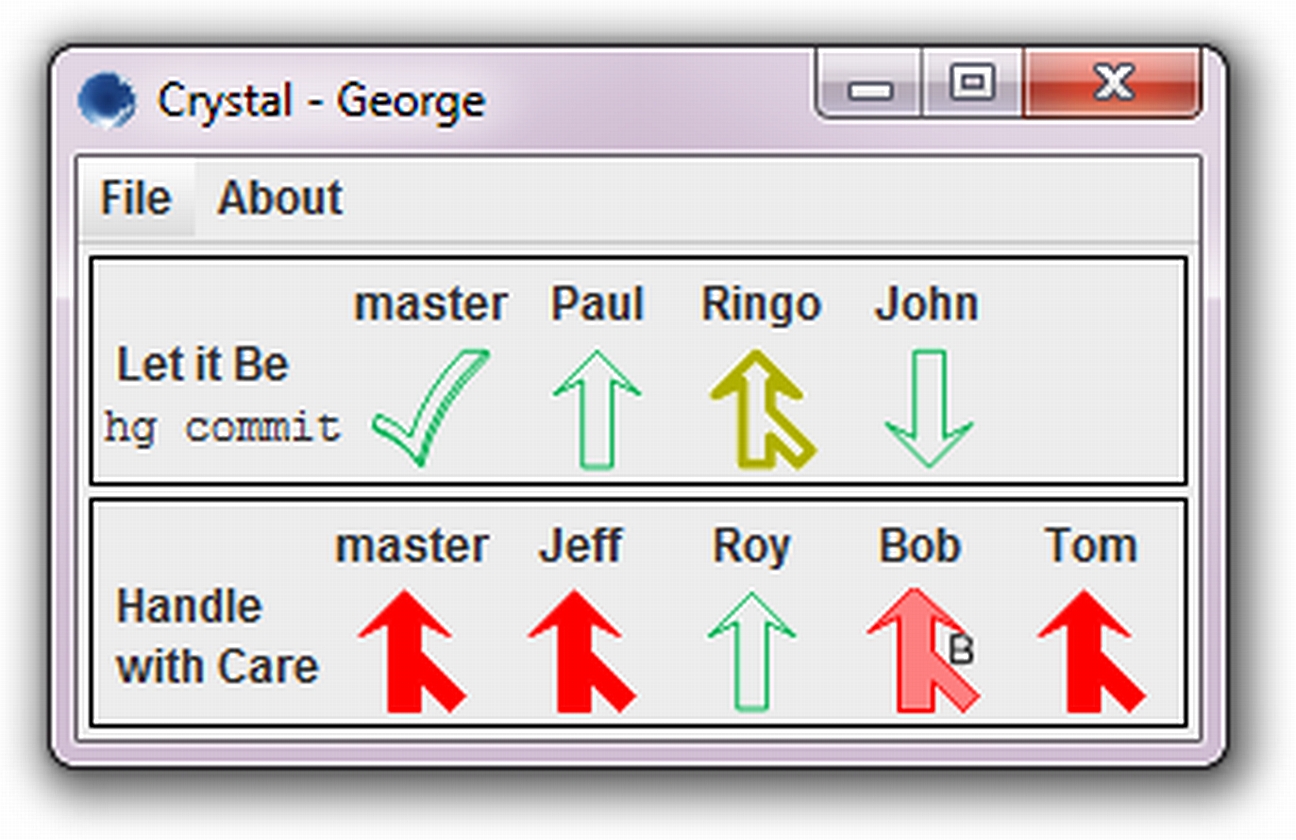 One of our most impactful projects, in terms of influence on industry and others’ research, has been work on collaborative development. Using our speculative analysis technology, we built Crystal, a tool to proactively detect conflicts between collaborating developers. Crystal automatically detects textual and behavioral conflicts that happen when multiple developers work in parallel, and unobtrusively informs the developers. This helps developers resolve, and even sometimes altogether avoid conflicts. The work won an ACM SIGSOFT Distinguished Paper Award at ESEC/FSE 2011, and an IEEE TSE Spotlight Paper recognition for the TSE extension (the two papers combined have been cited more than 300 times). This work directly led to new collaborative development tools and practices within Microsoft, and was awarded a Microsoft Research Software Engineering Innovation Foundation Award. An independent study found this work “the most industrially relevant software engineering research published in the prior five years, out of a total of 571 research papers.” This work influenced our 2017 development of FLAME that proactively detects architects’ conflicts during collaborative design. Awarded the Best Paper Award at IEEE ICSA, FLAME has led to industrial development of tools used internally by Infosys every day. Watch a video about Crystal.
One of our most impactful projects, in terms of influence on industry and others’ research, has been work on collaborative development. Using our speculative analysis technology, we built Crystal, a tool to proactively detect conflicts between collaborating developers. Crystal automatically detects textual and behavioral conflicts that happen when multiple developers work in parallel, and unobtrusively informs the developers. This helps developers resolve, and even sometimes altogether avoid conflicts. The work won an ACM SIGSOFT Distinguished Paper Award at ESEC/FSE 2011, and an IEEE TSE Spotlight Paper recognition for the TSE extension (the two papers combined have been cited more than 300 times). This work directly led to new collaborative development tools and practices within Microsoft, and was awarded a Microsoft Research Software Engineering Innovation Foundation Award. An independent study found this work “the most industrially relevant software engineering research published in the prior five years, out of a total of 571 research papers.” This work influenced our 2017 development of FLAME that proactively detects architects’ conflicts during collaborative design. Awarded the Best Paper Award at IEEE ICSA, FLAME has led to industrial development of tools used internally by Infosys every day. Watch a video about Crystal.
Privacy preservation in distributed computation
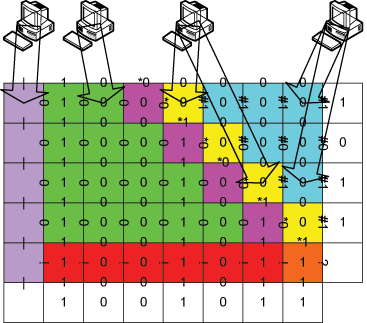 Our email, taxes, research, medical records are all on the cloud. How do we distribute computation onto untrusted machines while making sure those machines cannot read my private data? sTile makes this possible by breaking up the computation into tiny pieces and distributing those pieces on a network in a way that makes is nearly impossible for an adversary controlling less than half of the network to reconstruct the data. This work was awarded the SEAMS 2020 Most Influential Paper award. Watch a video about sTile’s impact, or read: Keeping Data Private while Computing in the Cloud.
Our email, taxes, research, medical records are all on the cloud. How do we distribute computation onto untrusted machines while making sure those machines cannot read my private data? sTile makes this possible by breaking up the computation into tiny pieces and distributing those pieces on a network in a way that makes is nearly impossible for an adversary controlling less than half of the network to reconstruct the data. This work was awarded the SEAMS 2020 Most Influential Paper award. Watch a video about sTile’s impact, or read: Keeping Data Private while Computing in the Cloud.